AI模型部署(2) - ONNX Runtime
ONNX Runtime 简介
ONNX Runtime (ORT) 是Microsoft开源的一个项目,用于跨平台的机器学习模型推理,支持多种编程语言和框架、操作系统及硬件平台。当一个模型从PyTorch、TensorFlow、scikit-learnd等框架转换为ONNX模型后,使用ONNX Runtime即可进行模型推理,而不再需要原先的训练框架。这使得模型的部署更为便捷和通用。此外,ONNX Runtime通过内置的图优化策略和集成的硬件加速库,可以获得更快的推理速度。即使是在相同的硬件平台,ONNX Runtime也可以获得比PyTorch和TensorFlow更好的运行速度。
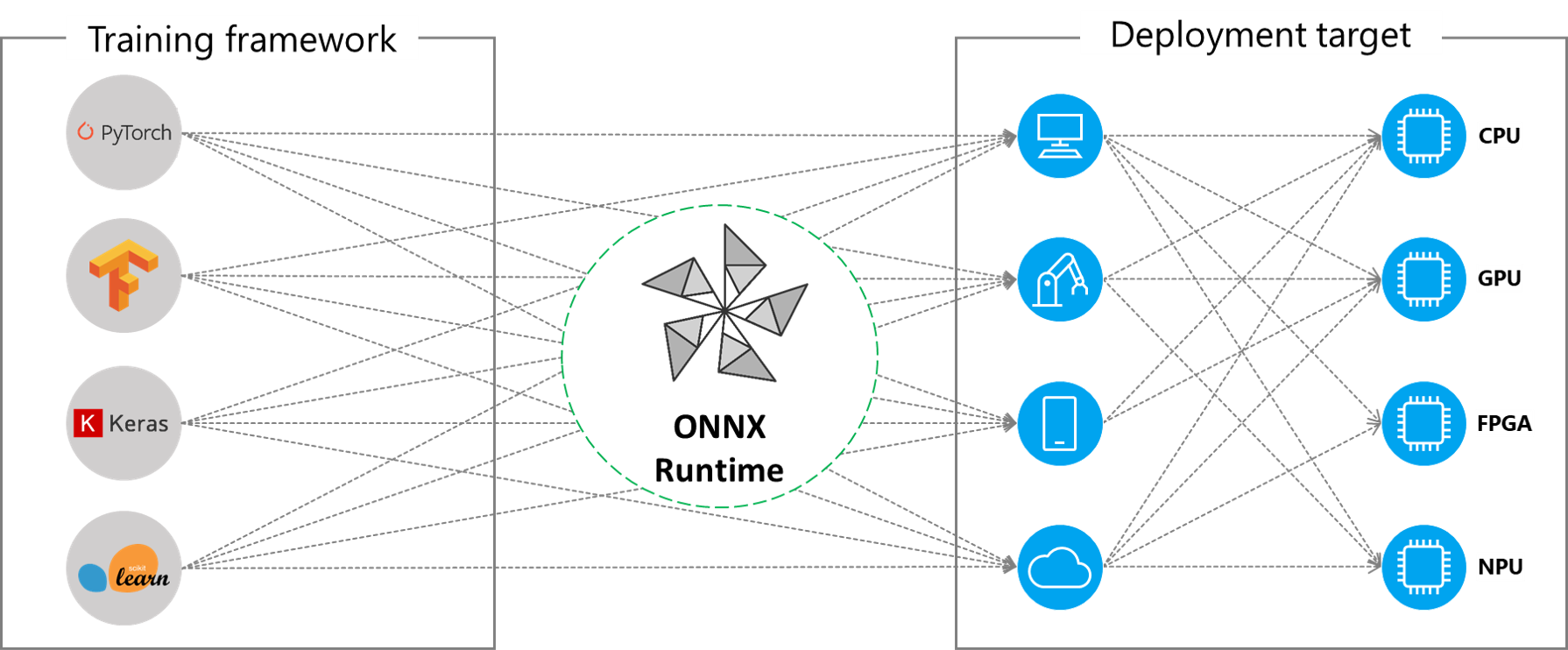
ONNX Runtime 推理
使用ONNX Runtime推理的流程为:
- 获取一个模型。可以使用任何深度学习/机器学习框架开发并训练,然后导出ONNX模型。
- 使用ONNX Runtime加载并执行ONNX模型。
- (可选)使用运行时配置和硬件加速优化模型的计算性能。
ONNX Runtime支持的编程语言有:Python、C++、C#、C、Java、JavaScript、Objective-C、Julia、Ruby等,支持的平台包括Windows、Linux、MacOS、Web Browser、Android、iOS等。
新版本的ONNX Runtime还支持加速PyTorch的模型训练过程。
Execution Providers (EP)
ONNX Runtime通过提供不同的Execution Providers (EP)支持多种硬件加速库,以实现同一个模型部署在不同的软件和硬件平台,并充分使用平台的计算资源和加速器,如CUDA、DirectML、Arm NN、NPU等,一种加速硬件或加速库实现为对应的EP。ONNX把算法模型表示为计算图模式,ONNX Runtime则把计算图的节点分配到对应的计算平台进行计算。但是,加速器可能无法支持全部的算子(Operator),而只是支持其中一个子集,因此对应的EP也只能支持该算子子集。如果要求EP执行一个完整的模型,则无法使用该加速器。因此,ONNX Runtime的设计并不要求EP支持所有的算子,而是把一个完整的计算图拆分为多个子图,尽可能多地把子图分配到加速平台,而不被支持的节点则使用默认的EP(CPU)进行计算。整个过程如下图:
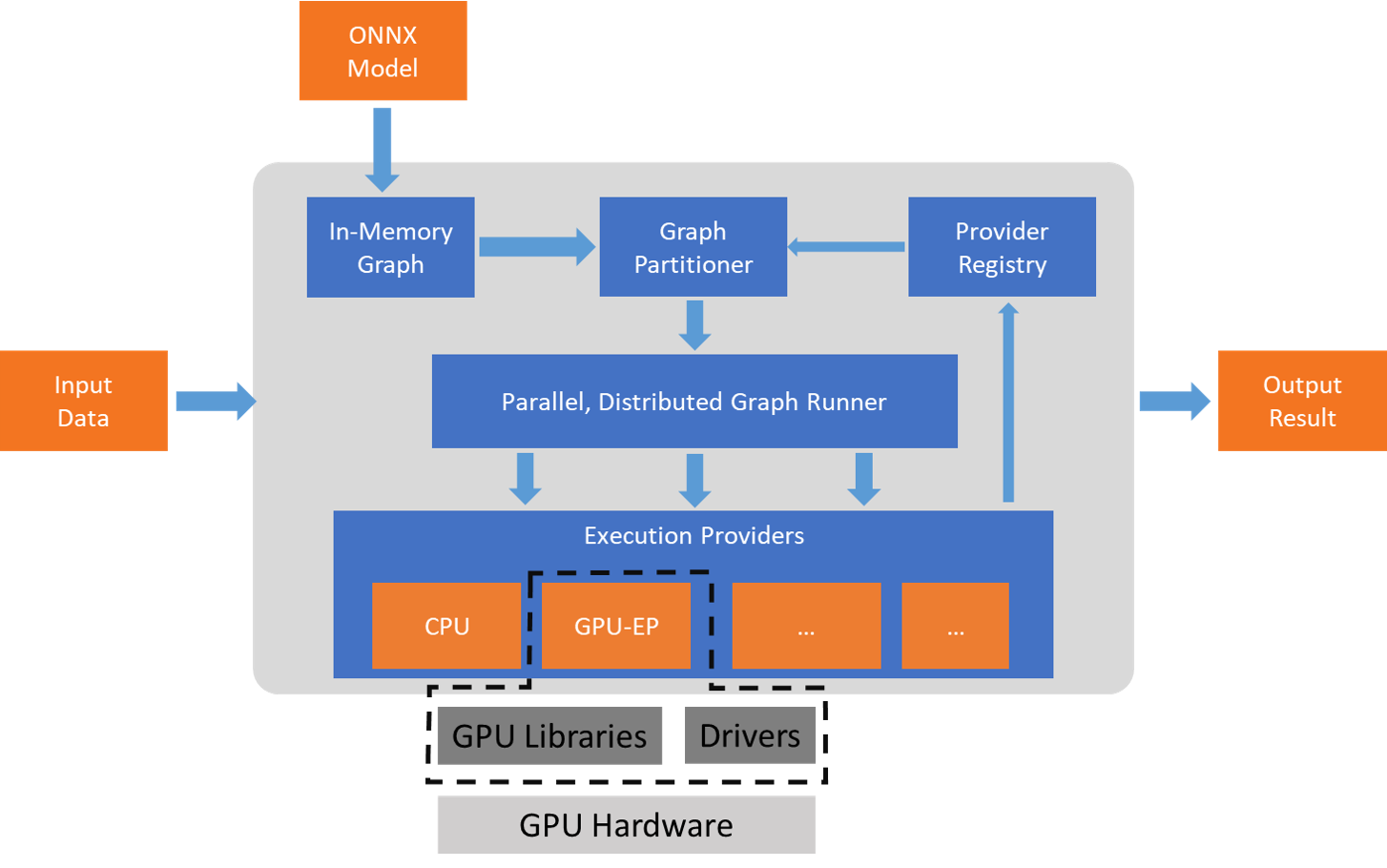
图优化 Graph Optimization
ONNX Runtime具有三个等级(Level)的优化,分别为:
- Basic (基础)
- Extended (扩展)
- Layout Optimizations (结构优化)
优化过程也是按顺序进行,即先进行Basic优化,然后进行Extended优化,最后执行Layout优化。其中Basic优化是平台无关的优化,在拆分子图之前进行。Basic优化主要是冗余的节点和计算,支持的优化有:
- Constant Folding(常量折叠):识别其中的常量表达式,对其进行求值,然后使用求值结果替代表达式,从而减少推理时的计算量;
- Redundant node eliminations(冗余节点消除):移除所有的冗余节点,如:
- Identity
- Slice
- Unsqueeze
- Dropout
- Semantics-preserving node fusions(节点融合):合并多个节点为单个节点,如对于Conv和Add两个节点,可以把Add算子合并为Conv的bias。支持的节点融合有:
- Conv Add
- Conv Mul
- Conv BatchNorm
- Relu Clip
- Reshape
Extended优化发生在拆分子图之后,实现更复杂的节点融合,目前只支持CPU和CUDA的EP。
Layout优化需要改变数据的结构,以获得更高的计算性能提升,目前只支持CPU的EP。目前支持的Layout优化为NCHWc Optimizer,即使用NCHWc结构,以增加数据的空间局限性,从而可以获得更好的加速性能,如使用AVX-2和AVX-512。
量化 Quantization
模型量化是把32-bit浮点型(float)的模型转换为8-bit(甚至4-bit)整型的模型。把32-bit的模型转换为8-bit的模型可以把模型大小减小到原来的1/4,同时可以使用加速指令和硬件(如AVX-2,AVX-512,以及NPU硬件),从而获得更快的执行速度。
References
- ONNX RUNtime Docs, https://onnxruntime.ai/docs/